字体选择
此开源项目并未设置LICENCE,但是我暂时没有发现比这个更好的字体了。开源中日英字体地址
组件中的Noto Sans-500有较好的兼容性。Noto Sans。该字体可以免费商用:
You can use them in your products & projects – print or digital, commercial or otherwise.
您可以在您的产品项目中使用它们-印刷或数字,商业或其他。
它的许可在这里许可
这里总结我自己使用Linux的过程中一些基础的指令以及gcc、python、cmake等开发工具的使用。适合未接触过Linux操作系统,想从macOS或者Windows操作系统转移到Linux操作系统的人入门阅读。
在使用Linux操作系统的过程中,你大多数时间会面对一个黑色的框框,它由指令和Log共同存在的模式,使得使用者可以快速的检查每一条指令的运行结果。指令的准确性能帮助开发者快速而精准地实现自己的想法。
Windows的设计理念就是让用户更少地使用指令,转而使用UI界面,所谓UI就是User Interface,但是到今天,这个UI的好用程度依旧不如指令。虽然UI大大降低了用户的学习成本,转而得到的是极低的使用效率。使用SHELL与机器快速的沟通是非常有必要的。
Windows的环境变量以及及其低效的注册表让我非常不喜欢它,对于环境变量的设置过于繁琐,注册表的可读性非常差。这些问题导致了Windows的SHELL难用而低效。沟槽的补全也是依托
WSL是Windows上的一个Linux子系统,实际上是通过虚拟机技术实现的,个人体验不错,不过苦于Windows的安装逻辑很难让人接受,安装WSL的难度不亚于学习如何安装Ubuntu——使用最多的Linux发行版。
接下来让我们开始Linux的学习吧!
这里我几个部分来介绍Linux的基础知识,除了Vim编辑器不是必须的以外,其他的章节几乎都是使用Linux必备的知识,请配合机器使用。跟着教程敲一敲这些指令,感受一下指令的魅力。
以下所有命令我都在Ubuntu22.04中测试通过。
开始,让我们看看当前目录有什么东西。ls命令可以列出当前目录的文件。默认不加参数的ls运行效果大概为这样:
1 | ls |

你会发现没有任何东西(或者有一些文件存在),这是因为ls默认只显示未隐藏的文件,在Linux中,以.开始的文件都会被隐藏,你可以使用ls -a来列出所有的文件。
1 | ls -a |

上面的命令虽然列出了所有文件的名字,但是我们不能得到文件除了名字以外的其他信息,我们可以使用ls -al来获取所有文件的信息:
1 | ls -al |

里面包括了很多信息,我们一一来讲:
然后我再解释一下第一行的意义drwx------
我们需要把它拆开来看,分成1 3 3 3来解析这一行,首先这一行是Linux中的权限标识,拆开之后分别是:
--- 当前用户组的权限--- 其他用户的权限- 表示无权限,r表示read可读,w表示write可写,x表示可执行。
前面的信息中,文件大小使用的单位是Byte这个单位不方便人类阅读,我们可以使用 -h参数来让这个大小转换为KB、MB、GB(根据文件大小自动转换)。
1 | ls -alh |

这条命令是我们最常用的,你可以一直使用这个。
cd命令相信你不陌生,在Windows中的SHELL里也存在这个命令,它的全称可能是Change dir或者Change disk,这些可以帮助你记住它,具体的使用方法是:
1 | # cd <dir> |
这条命令并不难理解,但是这里我需要给你讲解Linux中的路由机制。
Linux中存在两种路径格式
绝对路径以/开头,表示从系统的根目录开始索引,而相对路径不以/开头,表示从当前目录开始索引。
比如我们现在有这样的文件结构:
首先我们去到/home/zhywyt可以使用(注意,这条命令你可能无法运行,因为你没有这个目录,可以把zhywyt替换为你的用户名)。
1 | cd /home/zhywyt |
这里我们用的是绝对路径,然后我们想再去/root/.ssh/目录,上面的命令已经让我们到了/home/zhywyt/了,我们可以使用相对路径来路由到新的目录:
1 | cd ../../root/.ssh |
特殊的,Linux中还存在一个用户目录的概念,你可以使用
1 | cd ~ |
去到你当前用户的用户目录,除了root用户在/root/以外,其他用户都在/home/<用户名>下。
接下来我讲解一下Ubuntu(Linux 发行版)中的包管理器apt的基础使用。
首先我为你介绍一下apt的索引概念,apt包管理器使用软件源索引的方式来查找你需要的软件包,关于索引是什么,你可以访问这个链接来感受一下USTC镜像源,它其实就是apt帮你存储的软件对应下载地址的一个字典,你可以简单的通过软件名字来索引这些地址。理解了索引之后,再次面对apt 换源、apt update之类的问题你就会很清晰了。
我们的apt会先从你的软件源中获取索引,并保存在本地,下次需要的时候直接访问。但是由于软件源中的索引是动态更新的,所以我们需要定期运行更新索引的命令apt update,注意你要区分它和apt upgrade的区别。后者是用于更新软件包而非索引的。该命令非常危险。
请运行一下命令后继续后面的实验:
1 | apt update |
如果这个命令运行得非常缓慢的话,可能是因为你的源地址为国外,而你又没有开启代理。你可以选在开启代理或者UTSC apt 镜像源配置
或者简单的使用这一句命令更换镜像源:
1 | sudo sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list |
apt提供从索引中检索软件包的功能,比如我需要查找gcc软件包,我们可以运行此命令来查找:
1 | apt search gcc |
你会发现有非常多的输出,但是就是没找到你想要的gcc,你可以使用以下命令筛选结果中带gcc的索引:
1 | apt search gcc | grep gcc |
这条命令在后续的其他指令中详细介绍。

上面的命令执行之后还是有很多结果,但是我能找到自己想要的软件包,找到它的正确名字后你可以使用该命令安装它:
1 | sudo apt install gcc |
这里的sudo是因为我们的apt部分操作是需要管理员权限的,使用sudo可以借用管理员权限安装该软件包。
安装好之后,大部分软件包会为你配置环境变量,你可以直接使用gcc来访问该软件。更多的软件需要你自己探索。
如果你在网上下载了一个deb,也可以使用apt来进行安装。比如我们去网上下载一个linuxqq,QQ,选择x86下的deb下载。得到一个安装包,然后在下载目录打开终端
1 | # 注意这里输入你自己安装包的名字,并在前面加`./` |
下面的命令请勿运行
1 | sudo apt upgrade |
我们可以通过下面的命令检查我们已安装的软件包:
1 | apt list --installed |
请勿卸载
我们可以简单的使用
1 | sudo apt remove gcc |
来卸载gcc,但是这样的卸载方式不会清理该软件的配置文件、缓存。你可以添加--purge参数来清理他们:
1 | sudo apt remove --purge gcc |
由于软件包之间存在联系,在我们卸载了一些软件之后,会存在某些软件不再有意义的情况,但是apt不会帮我们清理他们,你可以运行
1 | sudo apt autoremove |
来清理这部分软件。这个命令是安全的,他不会删除你任何有用的软件包。
C/C++的开发工具我只介绍基础的编译器,关于调试器你可以自行STFW(Search The Fucking Web)。
Ubuntu默认安装gcc,但是你可以使用以下命令更新他们:
1 | sudo apt install gcc g++ |
然后在当前目录创建一个.c文件:
1 | touch first.c |
看不懂没关系,我只需要你能运行这些命令就行了,我来给你讲解重要部分:
1 | gcc first.c -o first |
这里输入了一个.c文件,并输出一个可执行文件first。(Linux操作系统中的可执行文件可以不需要后缀名)。
1 | ./first |
使用./来指定可执行文件并运行,如果你顺利的执行这些命令的话,你应该得到这样的输出:
1 | root@ffmpeg:~# ./first |
g++的使用和gcc的用法没有太大区别,但是g++还可以编译C++的代码,他们以.cpp结尾。
python可以讲的东西很多,这里我主要讲一下它的两个包管理器,一个是pip,一个是conda。其中pip只用于管理单环境的python包,而conda可以创建虚拟环境,分割不同的python环境。
建议所有的环境都使用codna配合pip使用
首先我们需要安装conda:
1 | wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh |
下面的<envname>指的是一个占位符,你可以替换为你需要的环境名字,后面的python版本也可以换。需要注意的是,conda指定包的版本使用=version,而pip使用==versino这是一个小区别,需要注意。
1 | conda create -n <envname> python=3.10 |
1 | conda env list |
1 | conda activate <envname> |
下面实例展示了安装numpy的方法。
1 | # conda install <pakName> |
1 | conda list |
1 | conda remove numpy |
pip是一个python包管理系统,一般会跟随python安装,pip的操作非常简单,速度非常快速。并且有大量的镜像源。
1 | pip install numpy |
1 | pip list |
1 | pip uninstall numpy |
我们一般使用conda创建虚拟环境,并使用pip安装我们需要的包,这样可以达到干净+迅速的包安装体验。
关于Vim编辑器,它是一个非常好用的文本编辑器,事实上这篇文章就是zhywyt使用该编辑器完成的,这可以让我在不使用鼠标和触摸板的情况下快速的定位我需要的位置。Vim的教程我暂时不写,这里给出我学习他的地址Just-Vim-It
这部分推荐廖雪峰的网站git教程
这部分以后再补细节。
grep使用字符串匹配,将输入中与pattern完全匹配的部分行筛选出来,你可以在测试这样一个命令:
1 | du | grep ssh |
这条命令会找到你的文件系统中你有权访问的所有路径中带ssh的文件。但是有时候我们想要获取pattern附近的信息,你可以使用-A(after)参数指定行后多少行的信息,类似的-B(before) 参数可以指定行前多少行的信息。
1 | du | grep -A 3 ssh |
尝试使用以下命令创建一个文件:
1 | touch file |
尝试使用以下命令创建一百各文件:
1 | touch file{1..100} |
尝试运行这些命令,思考运行结果:
其中SHELL是一个环境变量,应该是这样的记录SHELL=/bin/bash
1 | echo $SHELL $SHELL |
它的输出结果应该像这样:
1 | /bin/bash /bin/bash |
希望你发现了这些细微的区别。第一条命令,echo $SHELL $SHELL相当于echo接受了两个参数,所以他会让他们空一格并打印,而第二条命令echo "$SHELL $SHELL"只接受了一个参数,"$SHELL $SHELL"但是""会让包括的字符进行转义,比如"$SHELL"就应该转义为/bin/bash,而最后一条指令的'',会保持用户的所有输入,而不进行转义。
现在我们向一个文件中写入一些东西,之后会用到它。
1 | echo "info" > file1 |
cat命令可以读出文件中的所有东西,并打印自爱控制台上,文件可以是文本文件,也可以是二进制文件,只是会乱码,你只需要掌握它的输出就可以了。一般配合管道命令一起使用。
1 | cat file1 |
尝试使用以下指令创建一个文件夹
1 | mkdir testdir |
尝试使用以下指令删除刚刚创建的空文件夹
1 | rmdir testdir |
尝试创建一个非空的文件夹,并删除他们:
1 | mkdir testdir |
不出以意外的话它会提醒你这个文件夹是非空的。非空文件夹我们使用rm -r命令删除他们。
尝试使用以下命令删除前面使用touch创建的文件:
1 | rm file* |
尝试使用以下命令删除前面的非空文件夹:
1 | rm -r testdir |
-r的意思就是递归的删除,注意:该参数肥差能够危险,谨慎使用。
ln连接分成两种,一种是软连接,一种是硬连接。
1 | ln -s /path/to/source /path/to/destination |
软连接得到的结果是<destionation>是<source>的一个跳转,相当于不保存任何文件数据,只是保存了一条连接。
硬连接只能针对于文件,而软连接可以用于文件夹。
1 | ln /path/to/source /path/to/destionation |
需要注意的是硬连接得到的结果是同一个文件拥有两个不同的文件名(也可以相同,这里只绝对路径不同),对于操作系统来说这两个文件是平权的没有任何区别。
所有的连接操作中的路径都需要使用绝对路径!
1 | ps -axu |
自行查看输出,并尝试配合grep命令获取你想要的进程信息。
pgrep可以获取指定行的pid,pid是一个任务的唯一标识,用于查询进程的状态或者杀死它。我只用来杀死他们
1 | ps | pgrep ssh |
xargs可以将输入的数据分割、转化为后面指令的参数,你可以尝试配合pgrep使用批量杀死一些进程:
此命令会杀死ssh进程,请勿执行
1 | ps | pgrep ssh | xargs kill -9 |
重定向命令有两个,一个是>会先格式化目标再输入,另一个是>>,不会格式化目标,而是在后面添加。
1 | echo "zhywyt1" > test.txt |
值得一提的是,当文件不存在时,他会创建该文件,并写入。
管道命令是|,上面已经用的很多了,它可以把前一个命令的输出作为后一个命令的输入。
1 | cat test.txt |
尝试这些命令,并感受他们的作用。
普通的重定向只会把标准输出重定向到新文件,但是错误日志还是会输出到控制台,如果你想要所有的输出和日志全部重定向到文件你可以尝试这样的命令:
1 | cat file1 2>&1 > log.txt |
非常抱歉,我一下子无法找到很好的、简单的、带错误输出的例子,所以你可以在以后遇到此类问题的时候再尝试该操作。
ping命令非常简单,无需掌握太多参数,感兴趣可以自己查阅。ping命令可以接受ip或者域名。你可以尝试ping必应:
1 | ping cn.bing.com |
为什么不ping百度?
百度太垃圾了
traceroute命令和ping命令几乎没有使用区别。但是输出更加的精细,它会显示每一跳(一跳之经过一个路由器转发一次)的路径与时延。
1 | traceroute cn.bing.com |
看不懂没关系,学习了一些网络知识就能看懂了。
1 | ip addr |
全程其实不是ip addr而是ip address你甚至可以使用ip ad来调用它。输出请自行理解,需要一定的网络知识。
1 | ip route |
可以输出当前机器的所有路由表。
1 | netstat |
该命令可以直接运行,你可以看到所有的TCP、UDP、socket通信的信息。
1 | netstat -p |
该命令可以查询当前的正在使用Socket的程序识别码和程序名称。配合pgre获取pid并杀死他们!
可爱的室友说想玩本地部署的GPT,于是这里打算部署一个ChatGLM给他玩一下。这里记录部署过程。本地使用的机器如图。由于GLM需要大量的显存和内存,我使用的是PVE容器分配了32GB内存用于和显卡用于推理模型。

并使用conda安装环境。
1 | wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh |
请自行根据引导安装conda。装好conda之后重启终端,开始安装ChatGLM需要的环境。
cuda的安装方法你可以在这里找到cuda,不建议使用deb安装,而建议使用.run的方式安装,但是具体看你的设备环境能装上哪个版本。比如我需要12.4的cuda,所以我可以找到他并安装。
比如你要找<version>这个版本,你可以用这条链接找到他https://developer.download.nvidia.com/compute/cuda/<version>
1 | wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run |
如果你没有安装显卡驱动可以在这里同步安装,如果安装了的话,请不要重复安装。
你可能需要一点耐心,cuda的安装非常漫长,这是由于apt是单线程导致的。你可以尝试使用多线程的apt,但是我无法保证多线程编译是否正确。安装的同时你可以进行后面不需要cuda的部分。比如conda创建环境、模型下载等。
1 | # 创建虚拟环境 |
这里我使用了GLM4,我想配置一个GLM4-9b-chat
1 | git clone https://github.com/THUDM/GLM-4.git |
模型你可以在这里找到:Modelscope,lfs你可以在这里找到他的安装教程git lfs
1 | # 如果你没有安装git lfs |
我尝试了直接运行所有模型,你但是效果非常差,速度很慢。你可以在仓库下运行:
1 | # 注意你的运行位置 |
来尝试模型的效果,但是这份代码是不会进行量化的。
我这里放两份我成功运行的INT4量化代码,你可以尝试修改它并运行。
1 | (base) root@ChatGLM:~/GLM-4# git diff basic_demo/trans_cli_demo.py |
成功运行大概是这样的:
1 | (base) root@ChatGLM:~/GLM-4# git diff basic_demo/trans_web_demo.py |
这个运行结果大概是这样的:

问题描述:我在重装pve8.2.2恢复我的容器和虚拟机的时候,发现24.04的容器恢复时出现了如下错误:
1 | TASK ERROR: unable to restore CT 104 - unsupported Ubuntu version '24.04' |
在pve的论坛可以看到这篇文章:Ubuntu 24.04 - unsupported Ubuntu version ‘24.04’这里只是对文章进行一个梳理。
参见原文:Setup support Ubuntu 24.04 noble
1 | find / -name "Ubuntu.pm" |
它应该在/usr/share/perl5/PVE/LXC/Setup/Ubuntu.pm或者其他的地方,修改它。
1 | my $known_versions = { |
添加24.04这一行。
然后运行
1 | pveam available |
确保第二次运行pveam available的时候已经有system ubuntu-24.04-standard_24.04-2_amd64.tar.zst
然后参考这篇文章换源:PVE8修改软件仓库源和 CT模板(LXC)源为国内源,重要的是CT模板换源,如果已经换过了可以跳过。
最后下载24.04模板即可:
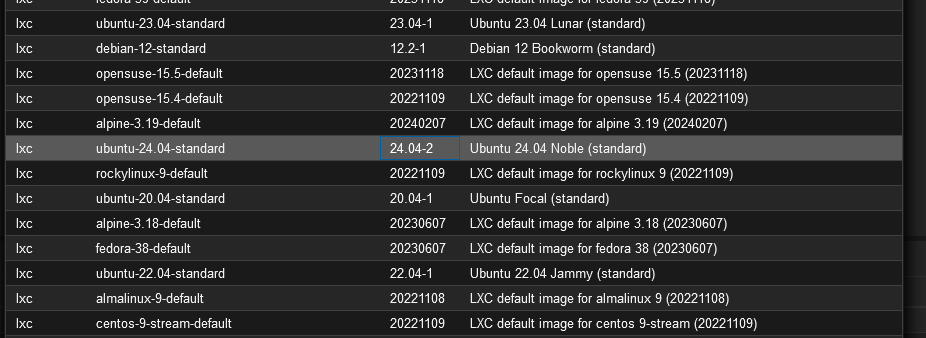
最后重新尝试恢复容器成功:
环境基础:
neofetch
1 | .-/+oossssoo+/-. root@zhy-cuda |
nvidia-smi
1 | Sun Jul 28 05:42:24 2024 |
直接来到官网安装,选择跳过注册即可:
https://www.anaconda.com/download/success
1 | wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh |
中途出现了一个路径错误,但是我并有中文路径,所以加上了两句export,之后正常安装。
然后重启终端。
1 | conda create --name nerfstudio -y python=3.8 |
到这里正常,然后需要安装一些包。这里加入代理
1 | # 设置代理 |
然后发现代理无效,于是使用清华源安装对应的库:
1 | pip3 install torch==2.1.2 torchvision==0.16.2 -i https://pypi.tuna.tsinghua.edu.cn/simple |
然后设置conda 清华源
1 | conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ |
然后安装
1 | conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit |
最后从源码安装nerfstudio即可:
1 | git clone https://github.com/nerfstudio-project/nerfstudio.git |
1 | # ~/.bashrc |
经过统计大家的投票结果,甲壳虫跑团管理层决定于2024年6月2号举行第一届百公里接力赛活动。活动奖励每位参与接力和摄影的同学迷你玻璃杯一个。

早上八点,在东操场开始了第一棒的出发,本次接力采取传递“跑表”的形式,每棒成员按照实力跑四到十六公里不等,鼓励大家陪跑跟随。大多数大学生还在赖床的时候,我们的运动员已经准备好,站在了起跑线上,第一棒出发的是我们的李幸同学,李幸是一位和蔼可亲的研究生学长,经常帮助刚入门的跑者拉伸、使用肌贴,以及纠正跑姿。另外两位是这次陪跑的同学。
很快便完成了第一棒的交接,三位小伙伴顺利的完成了第一棒的光荣任务。
中途是小伙伴们帅气的照片:
陈卓:
姚心淳:
溥黎翔:
诸威:
刘铭洋:
高德源:
华发兴:
张慧源:
觉华、袁嘉:
潘小超:
章侣楠:
最后一棒是我们的“跑神”章侣楠,大家一起和章神跑完了最后的八百米:
……还有很多小伙伴没有放在这里,大家可以去视频号或者bilibili-和杭电甲壳虫跑团来一场百公里的接力吧!看完整视频。
活动为大家准备了有糖可乐



